The logit lens can be deceptive if not used properly
The content of this short post will be already obvious to many researchers, but it's still worth writing out explicitly, especially when I see some assumptions that newer researchers are making.
Tldr: The logit lens is a convenient way to investigate internal representations. But it can be misleading, as it depends on the layer's basis vector alignment with the output space. Linear probes often show that decent representations can be present in much earlier layers than what the logit lens portrays.
The logit lens is a convenient proxy for capturing at what layer the neural net is able to correctly guess the output. This is useful when localizing where internal computations are happening.
Logit lenses can be more convenient than linear probes because you don't have to train anything new. You're just using the already-trained output classification layer as a linear probe.
However, the logit lens can be slightly misleading as it depends on the basis vectors of the internal representation being aligned with those of the output space. The logit lens does not necessarily capture the semantic content that is actually present at that layer. It may not be able to, if the representation space of that layer and the output space are not aligned.
For example, when running a logit lens on the CLS token in the residual stream of a vanilla vision transformer (pretrained to do 1k-way classification on ImageNet), there appears to be a dramatic "jump" in prediction between layers 9 and 10.
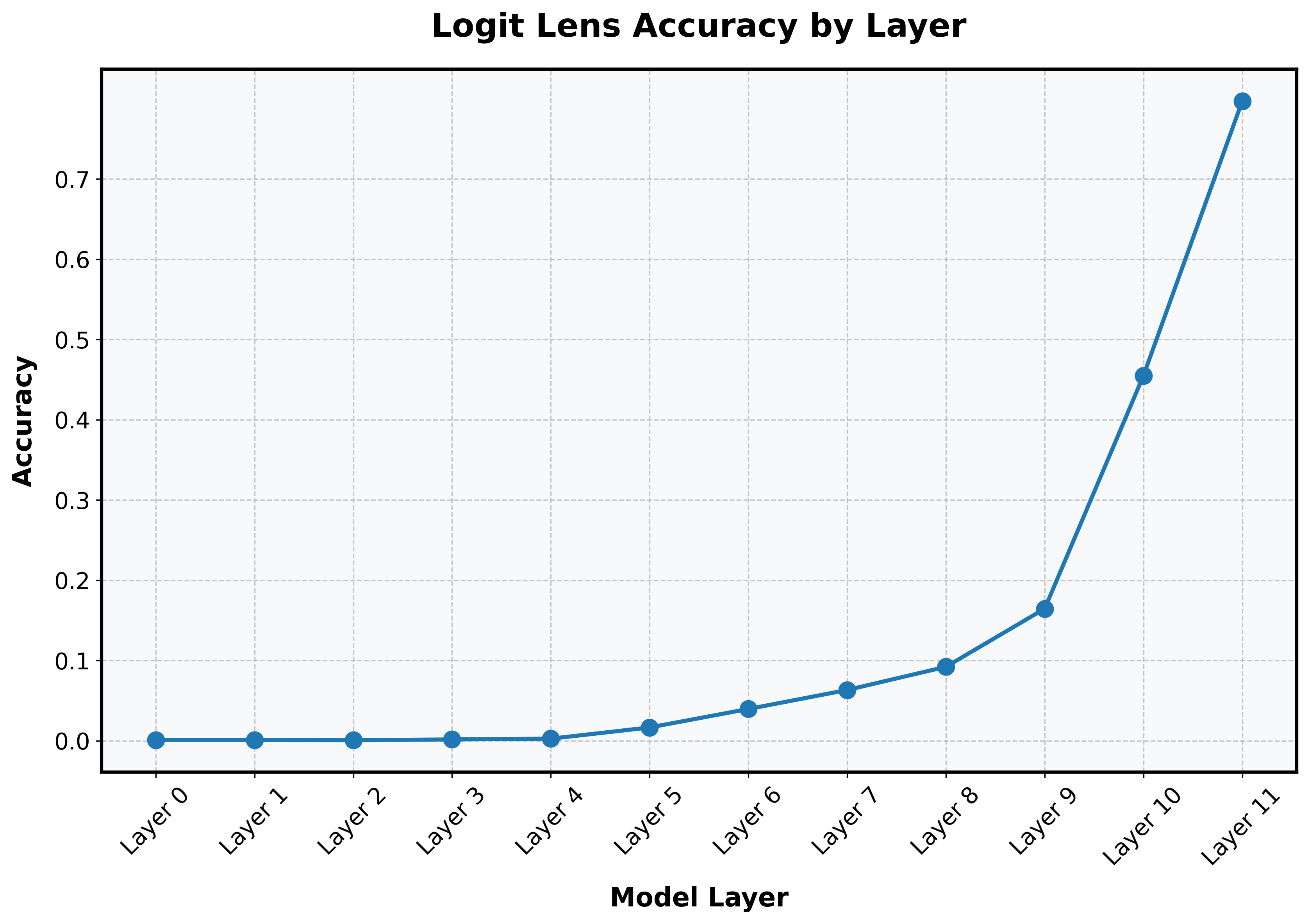
However, when I train a linear probe on every layer of the same vanilla vision transformer and evaluate accuracy on my test set, I get a different picture:
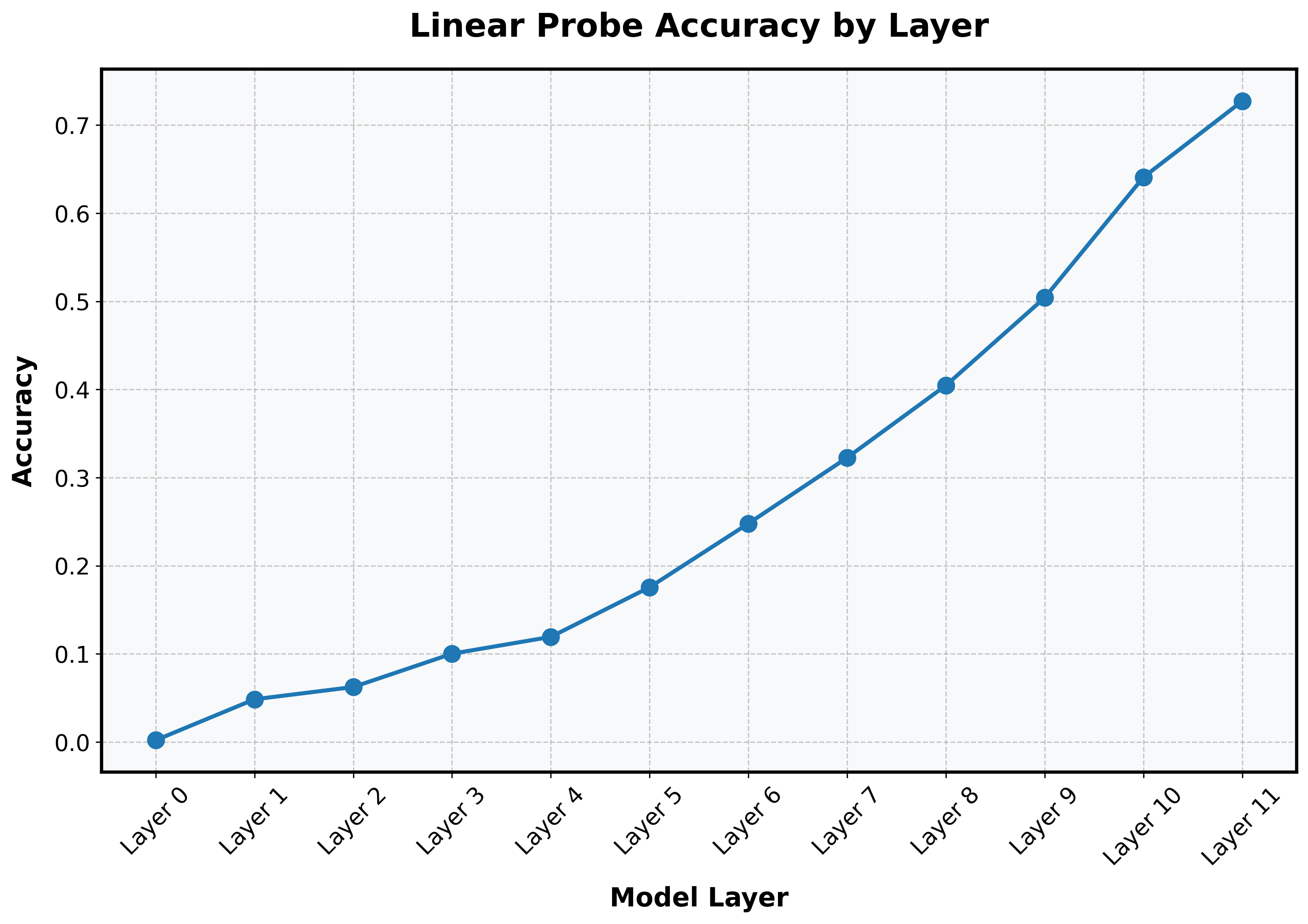
In the second graph, we see that the vision transformer is actually more gradually building the representation. Relevant information about the class is actually present quite early (~Layer 1) and increases pretty linearly. There are no dramatic jumps, as there are in the first graph.
Comparing the linear probe with the logit lens:
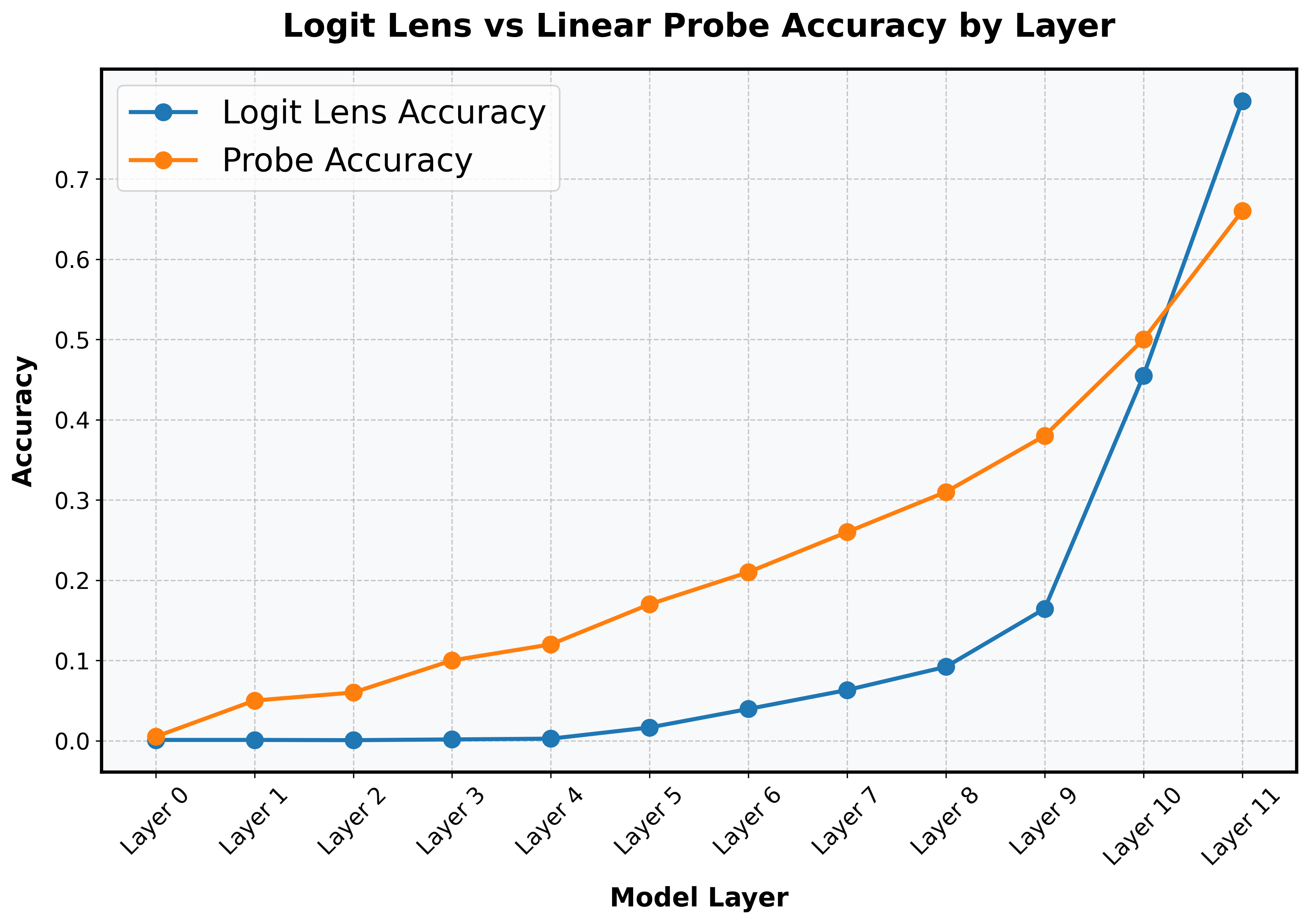
It is an interesting question when and why basis vector alignment occurs within the model. It is also an interesting question whether the alignment is a distinct signature of some other computational processing (what happens at Layer 9?). But these are different questions from "where internally does the model start making the correct prediction."
As a consequence, methods that depend on representation space alignment (like projecting CLIP vectors from intermediate layers into the output space) should be interpreted cautiously, especially for early and middle layers. These methods become more reliable in later layers, where internal representations start aligning with the output space. Methods like TunedLens try to deal with the distributional shift between layers but overall this space is underexplored.
Bottom line: When the logit lens fails to detect information, this doesn't mean the information is absent. The information may be present but encoded in a format that the pretrained linear transformation of the logit lens can't properly interpret, since it was primarily optimized for the final layer's representation. This is apparent to more experienced researchers, but not always to newer ones.
@misc{logitlensjosephclarification2025,
author = {Joseph, Sonia},
title = {The logit lens can be deceptive if not used properly},
year = {2025},
howpublished = {\url{https://www.soniajoseph.ai/the-logit-lens-can-be-deceptive-if-not-used-properly/}},
}[1] As a minor note, the probe accuracy does not reach logit lens accuracy due to having trained the probes from scratch (instead of initializing the probes to be the weights of the pretrained model's output layer). The original model was trained on ImageNet21k and fine-tuned on ImageNet1k while the probes were just trained on ImageNet1k, so the probes were trained on much less data.
Member discussion