Multimodal interpretability in 2024

I'm writing this post to clarify my thoughts and update my collaborators on multimodal interpretability in 2024. Having spent part of the summer in the AI safety sphere in Berkeley, and then joining the video understanding team at FAIR as a visiting researcher, I'm bridging two communities: the language mechanistic interpretability efforts in AI safety, and the efficiency-focused Vision-Language Model (VLM) community in industry. Some content may be more familiar to one community than the other.
As part of a broader series, this post is a progress update on my thinking around multimodal interpretability. It is a snapshot of a rapidly evolving field, synthesizing my opinions, my preliminary research, and recent literature.
This post is selective, not exhaustive, and omits many significant papers. I've focused on works that particularly resonate with my current thinking. Nor does this post fully represent my broader research agenda, but rather frames a few directions that I believe to be significant.
This post emphasizes mechanistic and causal interpretability, in contrast to "traditional" interpretability methods such as saliency maps, visualizations, and input-based techniques. We'll not focus on DeepDream-style approaches or Shapley scores. Instead of focusing on these feature visualizations, or on input data modifications common in mainstream interpretability, we'll concentrate on weight space analysis—examining how changes to the model's internal activations affect its behavior. Our goal is to develop a scientific, causal, and algorithmic understanding of the model by mapping its internal components to its behavior.
Overview
Multimodal interpretability methods:
- Circuit-based methods
- Text-image space methods
- Captioning methods
Circuit-based methods
Classical mechanistic interpretability focuses on the computational subgraph of the model as our representation. This view assumes that network's nodes, or "neurons," are a good enough unit of representation for the network's behavior. Circuit-based approaches include manual methods (Wang et al, 2023), automatic circuit discovery methods (Conmy et al., 2023), and optimizations for automatic circuit discovery's scalability, including attribution patching that employs linear approximations (Syed et al., 2023).
Other methods expand the computational subgraph with sparse autoencoders (Marks et al., 2024) to deal with superposition, or when the data has more features than neuron capacity. Sparse feature circuits use sparse autoencoder (SAE) features as finer-grained units of representation than neurons. Sparse feature circuits have been used in downstream applications in language models, including removing gender-related bias from a classifier.
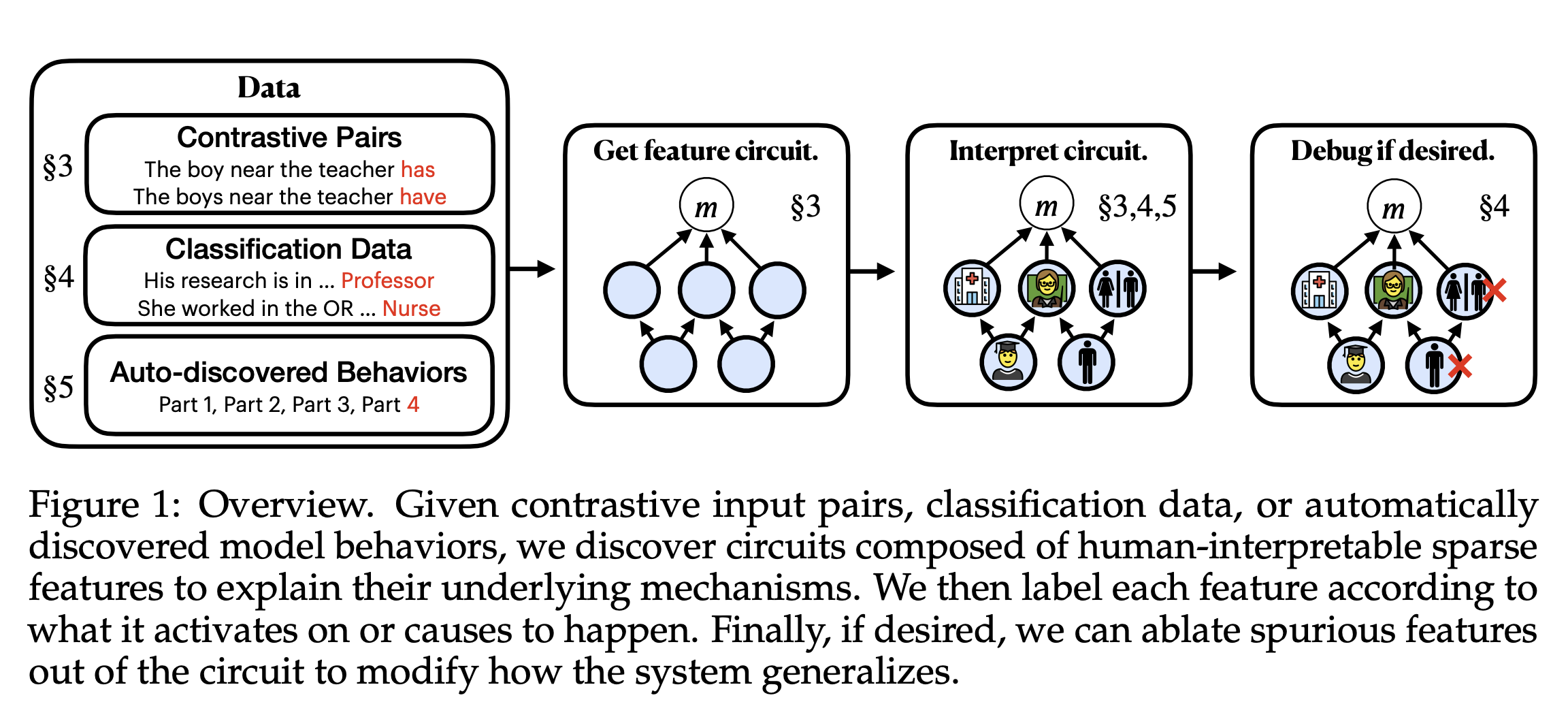
I like to think of sparse feature circuits as puppeteering the model's output in activation space, which is an alternative to fine-tuning the model's weights. You're essentially "decompiling" a model into a sparser representation, and performing circuit discovery on your new subgraph (Sharkey, 2024). The approach can be seen as analogous to LoRA (Hu et al., 2021), in that you are constraining your model's behavior, but in activation space instead of weight space. At present, this approach remains largely blue sky research. However, its potential applications are significant. It could allow for model customization through directly intervening on activations rather than weights, potentially reducing computational costs. Further, this method could allow us to audit our models for toxic or dangerous behaviors.
One critique of circuit-based approaches is that the network's representations may still be too distributed. Both the neurons, and even the finer-grained SAE features, may not be adequate units of representation to capture the model's behavior. There is evidence that neurons are only deceptively representative of the model's true behavior (Leavitt et al, 2020; Morcos et al, 2018; Amjad et al, 2019) and the same may apply to SAE features, although this hypothesis requires further testing. In the figure below, it is not obviously clear the extent that the pie-specific SAE feature impacts the classification of pie. Without causal testing, the pie feature may just be epiphenomenal and unrelated to the network's function. However, one advantage of mechanistic interpretability is that testing the pie SAE feature's effect on the output is relatively straightforward by ablating that neuron's activations.

As another issue, the precise activation value of a neuron might be crucial in ways that the simple scalar multiplication of your chosen features when steering your network (i.e. "clamping") may not properly capture. There is some evidence that the exact magnitude of neuron activation is significant for its encoding; for example, Goh et al. (2021) found a "politics neuron" that encodes for both Trump and LGBTQ values depending on its activation value.
I would love to see a study on the correlation between SAE feature interpretability and its model steering efficacy when clamped, particularly across different network layers and sublayers, and at different neuron activation magnitudes. That said, I haven't seen enough evidence that these methods won't take us quite far. I find these methods to be deeply conceptually pretty, and I am keen to see how far we can take them. The purpose of the Prisma project (Joseph, 2023), which has been my focus for the last few months, is to provide infrastructure for circuit-based interpretability on vision and multimodal models, leading up to sparse feature circuits with SAEs.
Finally, it's still unclear to me the extent that the current circuit-based and SAE efforts are rederiving the causal inference and disentanglement literature (Komanduri et al., 2024). However, the purpose of this older literature does not seem strongly focused on controlling or auditing the model, two motivations of mechanistic interpretability, so I imagine conclusions may look quite different this time.
Exploiting the shared text-image space
One technique quietly gaining popularity in multimodal interpretability is exploiting the shared text-image space of multimodal models. This technique is not prominent in classical language mechanistic interpretability.
This method, primarily applicable to models trained on contrastive loss between image and text, effectively provides "free" labels for the internal components of your vision encoder. By exploiting this shared text-image space, you can interpret the vision model's representations using the text encoder, without additional labeling.
Using the embeddings from the text encoder as basis vectors for the internal activations of the vision encoder
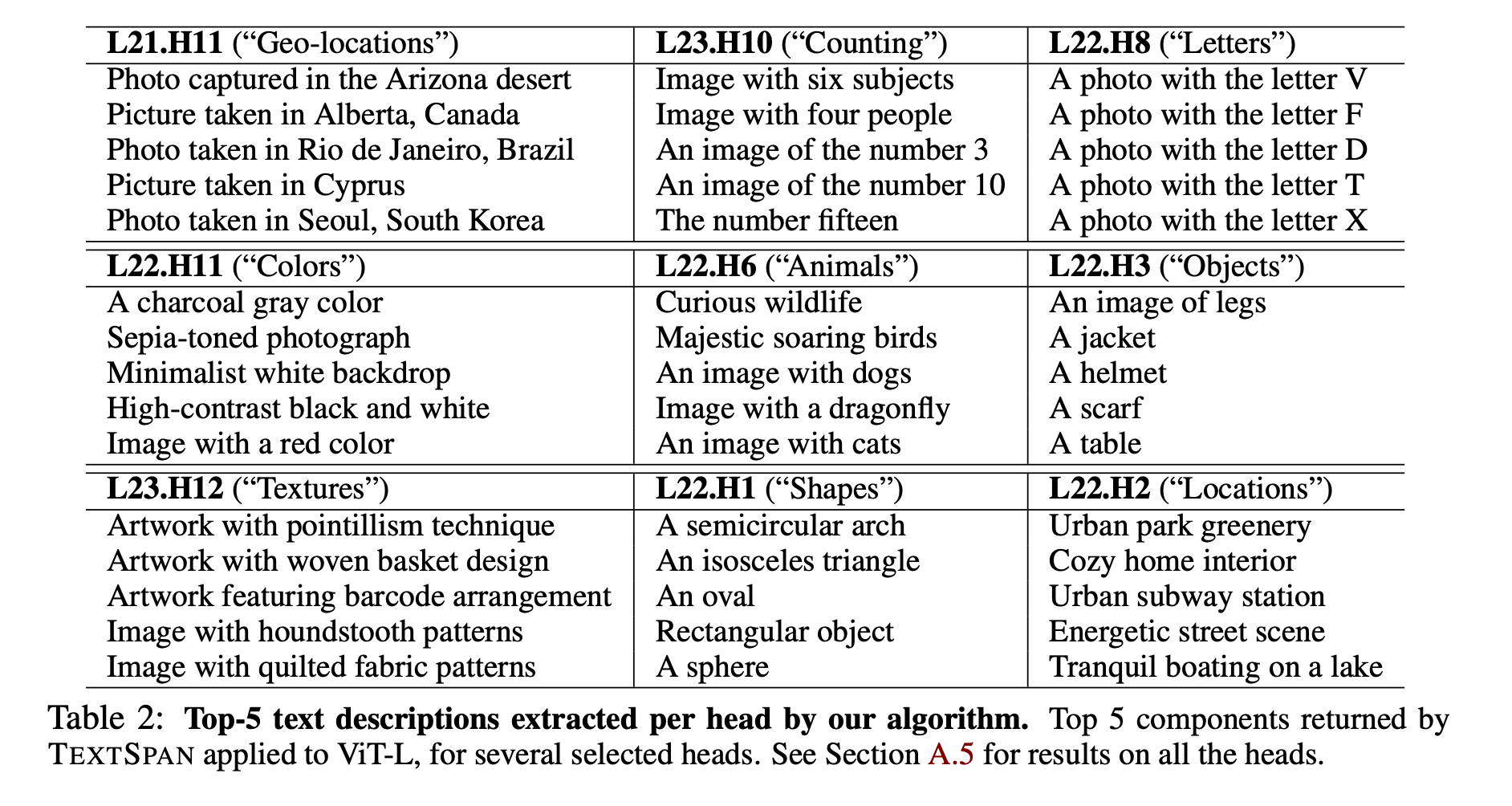
Gandelsman et al. (2024) introduce TEXTSPAN, an algorithm that creates a text-labeled basis for the attention head outputs of CLIP's vision encoder (Radford et al, 2021). The algorithm caches outputs for an attention head of the vision encoder, then greedily selects text embeddings from a precomputed text bank to maximize the explained variance of these outputs. The result is a set of basis vectors, each tied to a text description, which represents the behavior for each attention head of the vision encoder.
This approach resembles PCA on vision encoder attention head activations, except each basis vector corresponds to a specific text concept, which makes that attention head interpretable in English.
Finally, it's worth noting that TEXTSPAN relies on the assumption that the basis vectors in the final layers are sufficiently aligned with the output space for the technique to be effective. There is some evidence that the basis vectors only start to align at around Layer 9 of a 12 layer ViT (Joseph et al., 2024).
Extending the TEXTSPAN method to language mechanistic interpretability? I'd be keen to see the TEXTSPAN method applied to the attention heads of CLIP's text encoder (instead of the vision encoder as above), and for the method to be used more broadly in language mechanistic interpretability in general. I wonder how the text descriptions that TEXTSPAN generates might relate to the circuit-based attention patterns we've seen in language, like induction heads (Olsson et al., 2022). Do induction heads have corresponding English descriptions, or are they a too low a level of abstraction? I am not yet aware of any work that has bridged these two methodologies.
Another method that leverages the shared text-image space is CLIP-Dissect (Oikarinen et al., 2022), which focuses on individual neurons instead of attention heads.
More thoughts on using text embeddings for non-language interpretability
Leveraging the shared text-image space in the methods above assumes that the model was trained contrastively with language, like CLIP. However, there are many vision models that were not trained to be so granularly aligned with language, or with language at all. A vanilla ViT (Dosovitskiy, 2021) was trained with language in a very coarse-grained way (i.e. ImageNet classification) that does not create the continuous semantic space we see in CLIP. DINOv2 (Oquab et al, 2023) was trained in a purely self-supervised way, without text labels at all.
This raises a challenge: How can we apply text-based interpretation methods, like TEXTSPAN, to models such as a vanilla ViT and DINOv2, which lack aligned text embeddings? The absence of a native shared text-image space calls for additional steps.
We either need to either a) train aligned text embeddings for the ViT/DINOv2 vision embeddings (Method 1 below), or b) map the ViT/DINOv2 vision embeddings to CLIP-space (Methods 2 and 3 below).
We have a few options for "creating" a shared text-image space for image models that don't have one by default:
Method 1: Training a text encoder with a locked vision encoder
LiT (Locked Image Tuning) (Zhai et al., 2022) takes a pretrained vision encoder and trains a text encoder from scratch while keeping the vision encoder frozen, or "locked." Thus, you can decouple the vision encoder training method and data from those of the text encoder.
I really like this method of decoupling text and vision encoder data/training for several reasons:
- Computationally cheaper. LiT is cheaper than training both the image and text encoder together, as you're only updating the text encoder.
- Possibly more accurate. Decoupling the training methods and data of the encoders from each other may make the model more accurate and flexible. For instance, if I have a bunch of unlabeled images, I can train my vision encoder on the data in a self-supervised way without the corruptions of poor labels.
- Possibly less biased. Training the vision encoder using self-supervised learning (e.g. DINOv2) may create visual representations that are less biased by all the junk in the English language. This could mitigate a lot of the bias problems we're seeing with CLIP. Interestingly, you can also train multiple different text spaces while keeping the vision encoder locked. Thus you can cheaply train text encoders for multiple different cultures and languages and have them all share the same vision encoder.
Method 2: Training a CLIP adapter for the vanilla vision model output
Despite the perceived efficacy of LiT in generating a text-aligned space, training large models with a contrastive loss can still be expensive and bothersome, especially with RAM constraints.
Another solution for getting text embeddings for your vision-only model is training an adapter. Adapters are hacky, effective, and cheap to train.
An adapter is a lightweight neural net that maps from one basis space to another. For example, I can train an adapter that maps from DINO embeddings to CLIP embeddings using a contrastive loss between the DINO-CLIP embedding pairs. This technique is powerful because now I can take the cosine similarity between the DINO image embeddings and CLIP's text embeddings to classify my DINO embeddings. And the DINO model itself has never seen language!
Training adapters seems pretty common in the Stable Diffusion community, where fine-tuning or pretraining a diffusion model is often far more expensive than training an adapter. For example, say I want to generate images with a diffusion model from TinyCLIP-40M embeddings, but the diffusion model was finetuned on the different semantic space of ViT-L. We can train an adapter to map our TinyCLIP embedding to our ViT-L embedding, and then generate the image.
Below are the results of an adapter mapping TinyCLIP-40M embeddings to the ViT-L Kandinsky-2 encoder. The image of the man on the left is fed into a vision encoder (ViT-L), turning it into an embedding. This embedding is subsequently fed into a diffusion model to generate a new image from the embedding.
I trained an adapter, a simple four-layer neural network, that allows us to now use our TinyCLIP embeddings instead of ViT-L embeddings with the diffusion model. The adapter was trained with a contrastive loss between TinyCLIP and ViT-L embeddings. While the result is not perfect (the TinyCLIP embedding dude is not a super great reconstruction of the original image compared to the ViT-L embedding dude), it may be good enough for our purposes!

The pro of this method is that training an adapter is usually cheaper than training a text encoder from scratch like the LiT method. You can also leverage the richness of CLIP's text semantic space if you have a lot of image data but are scarce on text-data. You may not even need text data at all for this adapter method, which could be hugely convenient.
The con of this method is that you now inherit all of CLIP's biases. In scenarios where text data is extremely limited, this can be advantageous, as now you can leverage CLIP's rich text space. But if you're looking to train less biased models, or to explore semantic spaces distinct from CLIP's, then you may be better off with the LiT method mentioned earlier.
Method 3: Training a CLIP adapter specifically for vision model internal activations
"Decomposing and Interpreting Image Representations in Text in ViTs Beyond CLIP" (Balasubramanian et al., 2024) extends the TEXTSPAN method described previously to vision models that are not contrastively trained with language like CLIP. The method decomposes the internal contributions of a vanilla vision model into the final representation, and linearly maps these contributions to CLIP space, where you can do text interpretation.
The comparative effectiveness of TEXTALIGN versus the simpler CLIP adapter method remains unclear to me. TEXTALIGN potentially offers better interpretability by explicitly mapping the model's internal activations to CLIP space, rather than mapping just the final output representation. An empirical comparison of these two approaches would be valuable. It's also worth remembering that the original TEXTSPAN method relies on the assumption that the basis vectors in the final layers are sufficiently aligned with the output space for the technique to be effective.
Captioning methods
Instead of leveraging a shared text-image space, a totally different way of interpreting the function of a given neuron is to frame the task as a captioning problem. This technique identifies images that strongly activate the neuron or cause it to fire within a chosen interval, and then uses a VLM to describe these images.
You can then feed the autointerp text description generated by the VLM into a diffusion model to generate synthetic data, which you feed back into the neuron. This allows for an automated way to check for the accuracy of your description.
Of course, there are several issues that can arise if this is not done properly.
The first is interpretability illusions (Bolukbasi et al., 2021), or descriptions being too broad or too precise. For example:
- Overly Specific Interpretation: A neuron encoding for dogs in general might be mistakenly labeled as a Border Collie-specific neuron.
- Overly Broad Interpretation: Conversely, a neuron specifically tuned to Border Collies might be mistakenly labeled as a general dog neuron.
It would be interesting to mitigate this effect through autoprompting with an LLM to generate possible false positives or negatives and then test new examples with synthetically generated image data. For instance, the LLM could be tasked with creating prompts of varying specificity, from broad categories like "generate dog data" to highly specific scenarios such as "generate Border Collies turning their head to the left to look off into the sunset."
The second issue is that by using diffusion-generated images to verify your language descriptions, you're now relying on the data distribution of the diffusion model. This distribution might differ from that of the network you're trying to analyze. For instance, you might auto-label a neuron as encoding for "image of a ship," but when you generate images from this description, you end up with cartoon ships or something else outside the original distribution, like in the example below. You can try to constrain the data distribution with a prompt (like "photorealistic image of a ship"), but this approach may still not capture the original distribution of the model you're trying to analyze.
For scrappy interpretability work, this method might be sufficient, but the most reliable approach would be to train the diffusion model on the same data distribution as the model you're interpreting, although this is more resource-intensive.


The images generated by the diffusion model from the autointerp pipeline are out of distribution, even with appropriate constraints in the prompt. This example illustrates that mapping language to images is not always obvious, as the resulting image can take multiple subtle variations that language does not capture. a) An SAE feature from Layer 9 of TinyCLIP-40M. b) The resulting diffusion image generations from the autointerp prompt "image of a ship." The autointerp prompt was generated by feeding the image grid of ships into gpt4-o. Figure generated by me, please cite if used.
The third issue circles back to what I touched on earlier: I'm not convinced that examining only maximally activating images is sufficient for interpretability. There's some evidence suggesting that these peak-activation images for a given neuron don't necessarily predict its function. However, you could potentially mitigate this issue by captioning images from intervals across the neuron's activation distribution, rather than focusing solely on maximally activating images.
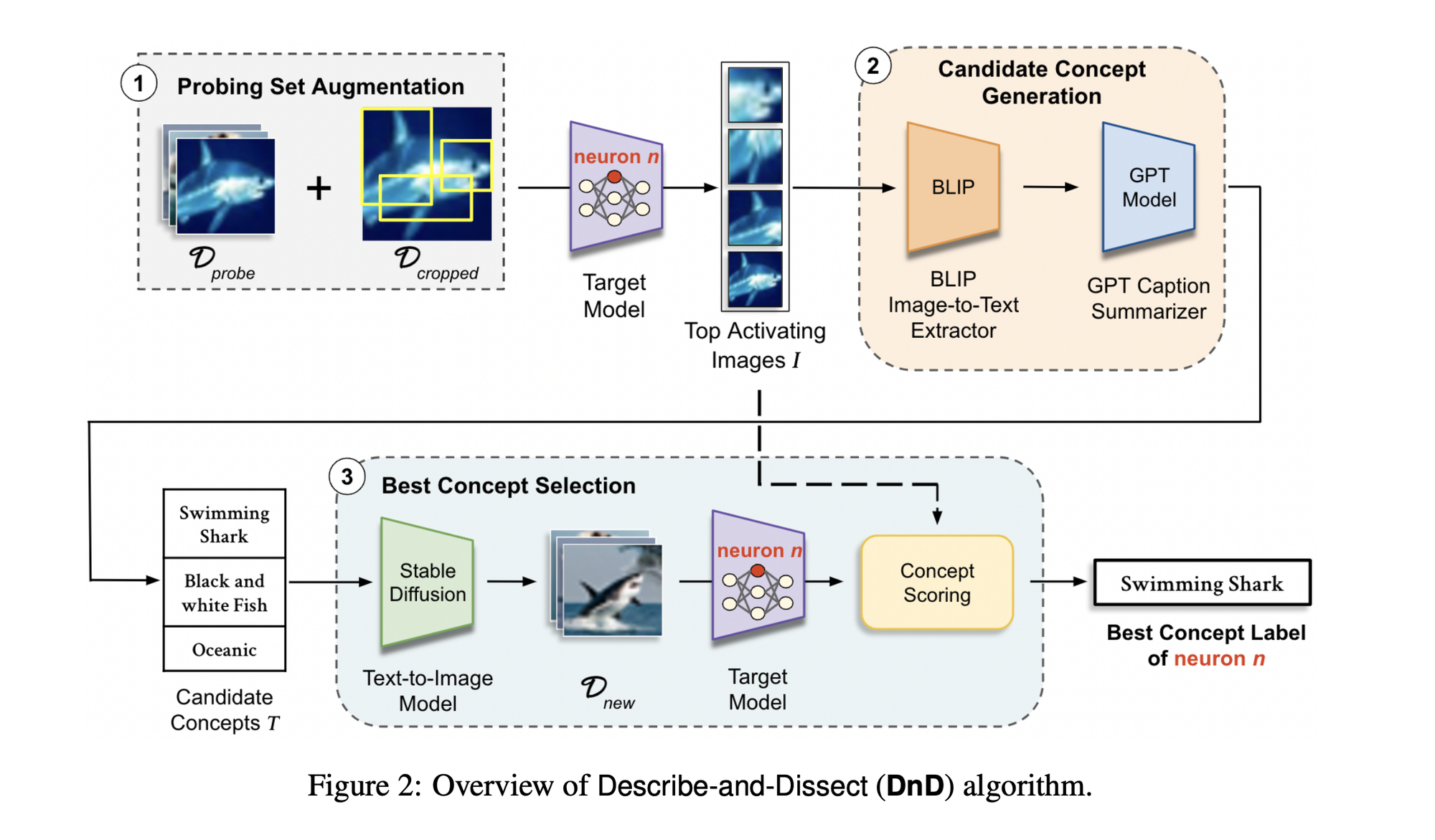
Putting these issues aside, Describe-and-Dissect (Bai et al., 2024) is one example of an interpretability pipeline that leverages diffusion models to generate synthetic data for autointerpretability as a captioning problem.
Interestingly though, when we were running autointerp/diffusion pipeline methods for Mindreader (MacCallum et al, 2024) last spring, we found they weren't quite good enough, even with some pretty aggressive prompting, as shown below. For instance, we'd show GPT-4 a bunch of images of frogs where the leaves were actually the activated part, but the model kept insisting the heatmaps were highlighting the frogs, completely missing the leaves. We tried to work around this by masking out the frogs, but then the model often didn't have enough context to make sense of what the heatmap was focusing on.


The Describe-and-Dissect pipeline is model-agnostic, so the method should improve as the model improves. That said, if you want good autointerpretability, it would be the most powerful to finetune a model on specific interpretability data, which I'll touch upon at the end of this post.
More comments
Several themes emerge throughout this post...
The three methods (circuit-based methods, SAEs, leveraging a shared text-image space, and captioning neurons) are synergistic
To interpret a non-language model, I'd use the three methods described above: circuit discovery for behavior-specific features, text-image labeling, and captioning neuron activations.
Circuit methods establish causal links between components and outputs, checking your language labeling. SAEs disentangle representations, enabling further analysis of refined features. Text-image space and neuron captioning provide human-readable descriptions. You can also compare the agreement of the last two methods– i.e. would both text-image space methods and captioning methods lead to the same interpretation of a given attention head?
It is still unclear if neurons or SAE features are the best unit of representation
It would be interesting to benchmark neuron and SAE feature steerability due to mixed evidence on neurons as good units of representation. The superiority of SAE features for interpretability and steering is also insufficiently studied.
Maximally activating images may not accurately represent neuron function, as multiple neurons might combine nonlinearly. Neurons may have context-dependent functions, potentially complicating network steering beyond naive clamping.
Superposition's validity as a mental model is still questionable to me. Seemingly, it's often confused in practice with mixed selectivity based on neuron magnitude, especially when many interpretability studies only look at the top N images, and not images in other neuron intervals. Some of these studies then seem to conclude that SAEs alleviate superposition when really they may alleviate mixed selectivity.
Fine-grained language data is critical
Data is king here. The semantic space you're creating seems to start with how the data is labeled, which sets the precedent in the beginning.
For example, if I wanted to check how vJEPA encoded for intuitive physics, the foremost bottleneck is that intuitive physics video data isn't often labeled in a fine-grained way, with task-relevant captions such as "object permanence." Thus it may be tricky to find the relevant English labels, even if I successfully run my autointerp methods on the model. Ultimately, data starts with humans, with high quality data sets and labelers.
Lack of gold standard for interpretability
Currently, the field sometimes relies on vague assertions about the interpretability of various layers and sublayers, and how interpretability scales with model size. These claims often have the epistemic status of folklore rather than scientific findings. It would be nice to see more definitive results.
To address some of the issues above, we're collecting an interpretability dataset to gain a thorough understanding of the model, and to benchmark autointerp methods.
This dataset will also allow us to test hypotheses about the function of a given neuron, the effectiveness of different representation units (i.e. neurons vs. SAE features), and the validity of concepts like superposition in a more controlled manner.
I'll share more details about this dataset and its potential impact in a future post.
I'll release two additional posts soon:
a) Building a gold standard vision transformer interpretability dataset, and pilot results. The dataset alone will both tell us more about the organization of a vision transformer than before, and give us a better ground truth for general vision autointerp methods. We are creating this dataset in collaboration with the data-labeling company Pareto.
b) Why multimodal mechanistic interpretability is significantly different from language mechanistic interpretability, and why assuming that the former is simply an extension of the latter is a mistake. While this may be intuitive for some industry and academic communities, this is not the mainstream narrative in the AI safety community, whose multimodal research is currently underdeveloped.
Citation
Are you referencing this blogpost elsewhere? Please cite as below. Thank you for reading!
@misc{Joseph2024,
author = {Joseph, Sonia},
title = {Multimodal interpretability in 2024},
year = {2024},
howpublished = {\url{https://www.soniajoseph.ai/multimodal-interpretability-in-2024/}},
}
Acknowledgements
Thank you to everyone for the discussions. Thank you to the Prisma team, the Summer 2024 MATS cohort, and the JEPA team at FAIR. Thank you to individuals for the ongoing dialogs, including my advisor Blake Richards, Yossi Gandelsman, Cijo Jose, Koustuv Sinha, Praneet Suresh, Lee Sharkey, Neel Nanda, and Noah MacCallum. This list is incomplete!
References
-
Amjad, R. A., Liu, K., & Geiger, B. C. (2021). Understanding neural networks and individual neuron importance via information-ordered cumulative ablation.
-
Balasubramanian, S., Basu, S., & Feizi, S. (2024). Decomposing and interpreting image representations via text in vits beyond CLIP. In ICML 2024 Workshop on Mechanistic Interpretability.
-
Bolukbasi, T., Pearce, A., Yuan, A., Coenen, A., Reif, E., Viégas, F., & Wattenberg, M. (2021). An interpretability illusion for bert.
-
Conmy, A., Mavor-Parker, A. N., Lynch, A., Heimersheim, S., & Garriga-Alonso, A. (2023). Towards automated circuit discovery for mechanistic interpretability.
-
Dosovitskiy, A., et al. (2021). An image is worth 16x16 words: Transformers for image recognition at scale.
-
Gandelsman, Y., Efros, A. A., & Steinhardt, J. (2024). Interpreting CLIP's image representation via text-based decomposition.
-
Goh, G., et al. (2021). Multimodal neurons in artificial neural networks. Distill. https://distill.pub/2021/multimodal-neurons
-
Hu, E. J., et al. (2021). LoRA: Low-rank adaptation of large language models.
-
Joseph, S. (2023). ViT Prisma: A mechanistic interpretability library for vision transformers. https://github.com/soniajoseph/vit-prisma
-
Joseph, S., & Nanda, N. (2024). Laying the foundations for vision and multimodal mechanistic interpretability & open problems. AI Alignment Forum.
-
Komanduri, A., Wu, X., Wu, Y., & Chen, F. (2024). From identifiable causal representations to controllable counterfactual generation: A survey on causal generative modeling.
-
Leavitt, M. L., & Morcos, A. (2020). Towards falsifiable interpretability research.
-
MacCallum, N., & Joseph, S. (2024). Mindreader: Interpreting Vision Transformer Internals. Retrieved from https://mindreader-web.vercel.app/
-
Marks, S., et al. (2024). Sparse feature circuits: Discovering and editing interpretable causal graphs in language models.
-
Moayeri, M., Rezaei, K., Sanjabi, M., & Feizi, S. (2023). Text-to-concept (and back) via cross-model alignment.
-
Morcos, A. S., Barrett, D. G. T., Rabinowitz, N. C., & Botvinick, M. (2018). On the importance of single directions for generalization.
-
Oikarinen, T., & Weng, T. (2023). CLIP-Dissect: Automatic description of neuron representations in deep vision networks.
-
Olsson, C., et al. (2022). In-context learning and induction heads.
-
Oquab, M., et al. (2024). DINOv2: Learning robust visual features without supervision.
-
Radford, A., et al. (2021). Learning transferable visual models from natural language supervision.
-
Sharkey, L. (2024). Sparsify: A mechanistic interpretability research agenda. AI Alignment Forum.
-
Syed, A., Rager, C., & Conmy, A. (2023). Attribution patching outperforms automated circuit discovery.
-
Wang, K., et al. (2022). Interpretability in the wild: a circuit for indirect object identification in GPT-2 small.
-
Zhai, X., et al. (2022). LiT: Zero-shot transfer with locked-image text tuning.
Member discussion